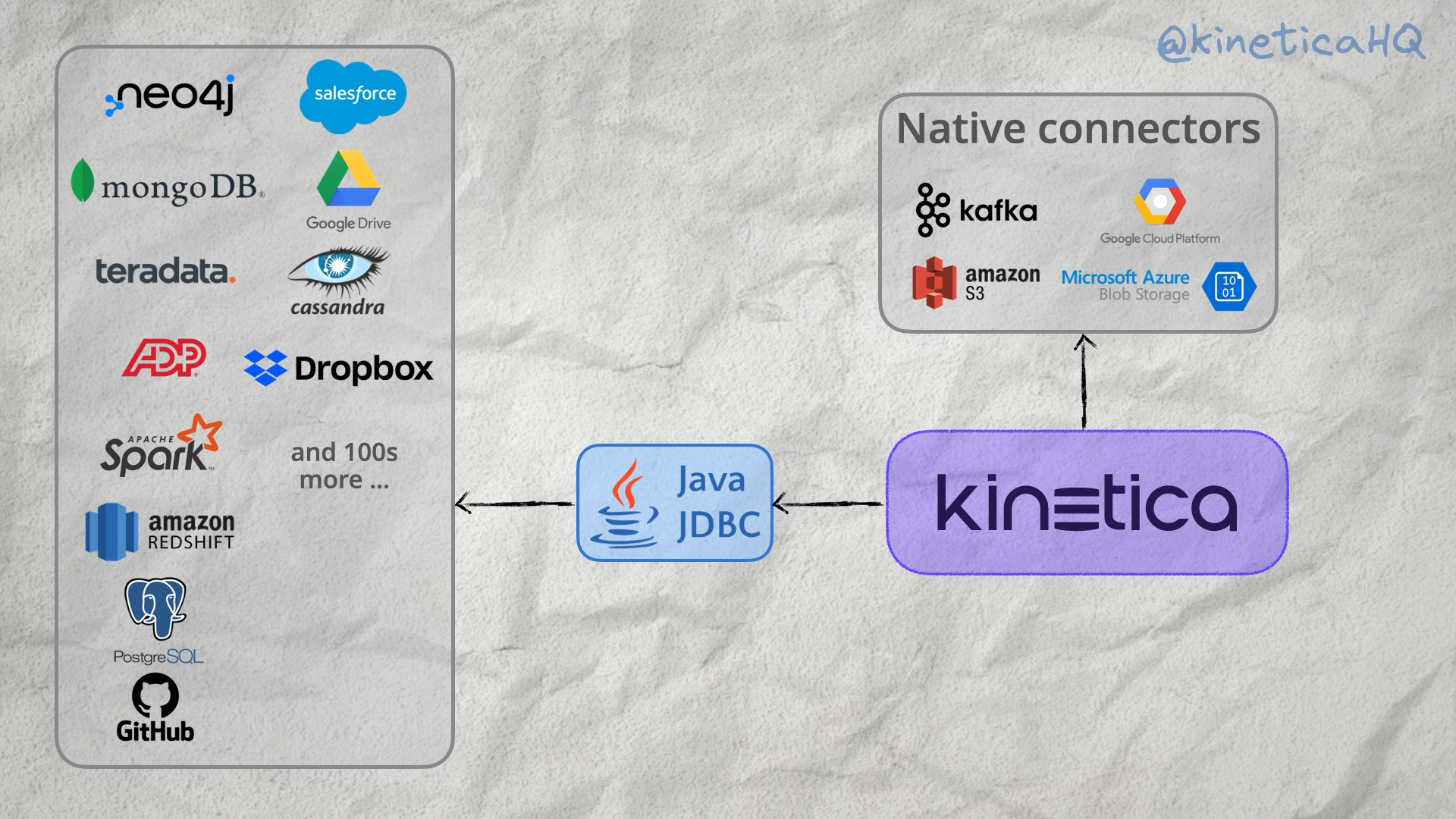
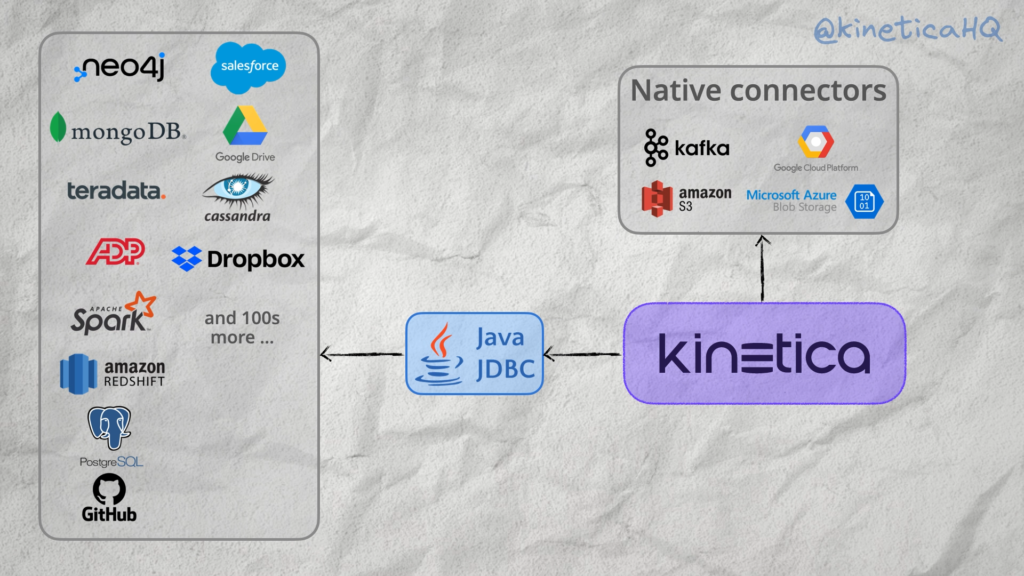
A modern business relies on a variety of repositories for data. These include databases like Postgres, object stores like AWS S3, event stores like Apache Kafka, file storage solutions like Google Drive and applications like Salesforce and HubSpot.

All of these databases and applications serve specific business needs. For instance, an online retail business might use Apache Kafka to record customer interaction with their website, Cassandra for long term data storage, Hubspot for managing business relationships and dropbox for managing internal files.
Analytical databases like Kinetica need to be able to access and analyze data from all of these different sources in an easy and performant manner.
But this is easier said than done. Each of these repositories have their own often unique take on how to represent, store and provide access to data. This blog explains how Kinetica uses JDBC (Java DataBase Connectivity) and drivers provided by the data connectivity platform CData to address this challenge.
There’s also a sample workbook at the end of this blog that uses JDBC to connect and load data from a google spreadsheet and a Postgres database. You can try that for free with Kinetica Cloud
An emphasis on ease of use
Kinetica is known for its speed. Its high performance vectorized engine and custom built library of geospatial, graph, OLAP and time series functions allow you to do complex analytical tasks on extremely large data.
Over the last year, we have added several ease of use features that now couple our industry-beating performance with a frictionless user experience. These include a rich and interactive SQL notebook environment called Workbench, a Postgres wireline that allows users to simply point existing applications that use Postgres syntax to Kinetica without having to refactor code and JDBC data sources that allow you to connect to hundreds of different data sources with ease.
The last feature discussed above – JDBC data sources – is key to Kinetica’s ability to plug into a variety of data repositories. Let’s take a closer look.
Two paths – Custom connectors or JDBC
Generally speaking, there are two ways to establish a connection with a data source – you could either build a custom connection from scratch, or you could rely on an existing protocol.
Custom connectors offer the greatest amount of flexibility and control over performance, since you can tweak and tune it so that it best suits your needs. Custom connectors are however, difficult and time consuming to build and maintain.
Generalized protocols like JDBC on the other hand, provide an out of the box experience when it comes to connecting to a data source. But they offer, lesser degree of flexibility and control since you have to rely on the generalized interface provided by the JDBC driver rather than one that you have tuned to work best with your solution.
At Kinetica, we have opted for a hybrid approach.
We provide custom interfaces for all the data sources that we are tightly coupled with. These include batch data stores like HDFS, AWS S3, Azure blob store and Google Cloud Platform and the most popular solution for streaming data, Apache Kafka. For everything else we provide an interface via JDBC.
What is JDBC?
JDBC stands for Java DataBase Connectivity. It is a standardized API for interacting with databases using Java programs. With JDBC developers don’t have to worry about building custom connectors for interacting with a new database. Instead, you can use JDBC as a middle layer that provides a standardized interface to connect, issue queries and handle results from a database.
The only requirement is that the application or database that you are connecting to has a JDBC driver. And this is where Kinetica’s partnership with CData comes into play.
Access 100s of data sources using CData
CData is a data connectivity platform that provides JDBC drivers for hundreds of databases and applications.
These include NoSQL databases like MongoDB, Redis and Cassandra, relational databases like Postgres, MySQL and Oracle, File stores like Dropbox and Google Drive and business tools like Salesforce, Google Analytics and NetSuite.
CData does all the work of creating and maintaining all the JDBC drivers that provide access to data from all of these data sources. And as a user of Kinetica, you get access to all of these drivers for free.
Now, let’s see how you can use a JDBC driver to connect to a data source.
Connect with just two queries
Now, there are two ways in which you can use a JDBC driver to connect to a data source. You can load your own driver into Kinetica or you can reference a CData driver. The example workbook shared at the end of this blog uses both routes. We use the CData driver to access data from a google spreadsheet and then we load a publicly available driver into Kinetica to connect to a Postgres database.
No matter the path, the steps for loading data are easy and intuitive. The code below shows how to connect to a postgres database using a JDBC driver for postgres.
First you create the data source. This requires the location of the database along with the credentials for accessing it. In the options, we specify the location of the JDBC driver and the driver class.
CREATE OR REPLACE DATA SOURCE postgres_ds
LOCATION = ‘jdbc:postgresql://mydb.com:5432/db'
USER = ‘myusername’
PASSWORD = ‘mypassword’
WITH OPTIONS (
JDBC_DRIVER_JAR_PATH = 'kifs://drivers/postgresql-42.3.6.jar',
JDBC_DRIVER_CLASS_NAME = ‘org.postgresql.Driver’
);
And then you specify the table in Kinetica and the name of the file or the query that selects the data that you want to load into it from the data source created in the previous step.
LOAD DATA INTO my_kinetica_table
FROM REMOTE QUERY ‘SELECT * FROM public.large_table’
WITH OPTIONS (
DATA SOURCE = 'postgres_ds'
);
That’s it – just two simple SQL queries. We can use the same pattern as shown above to connect to hundreds of different data repositories using either custom connectors or JDBC. All you need are the connection details and the relevant credentials.
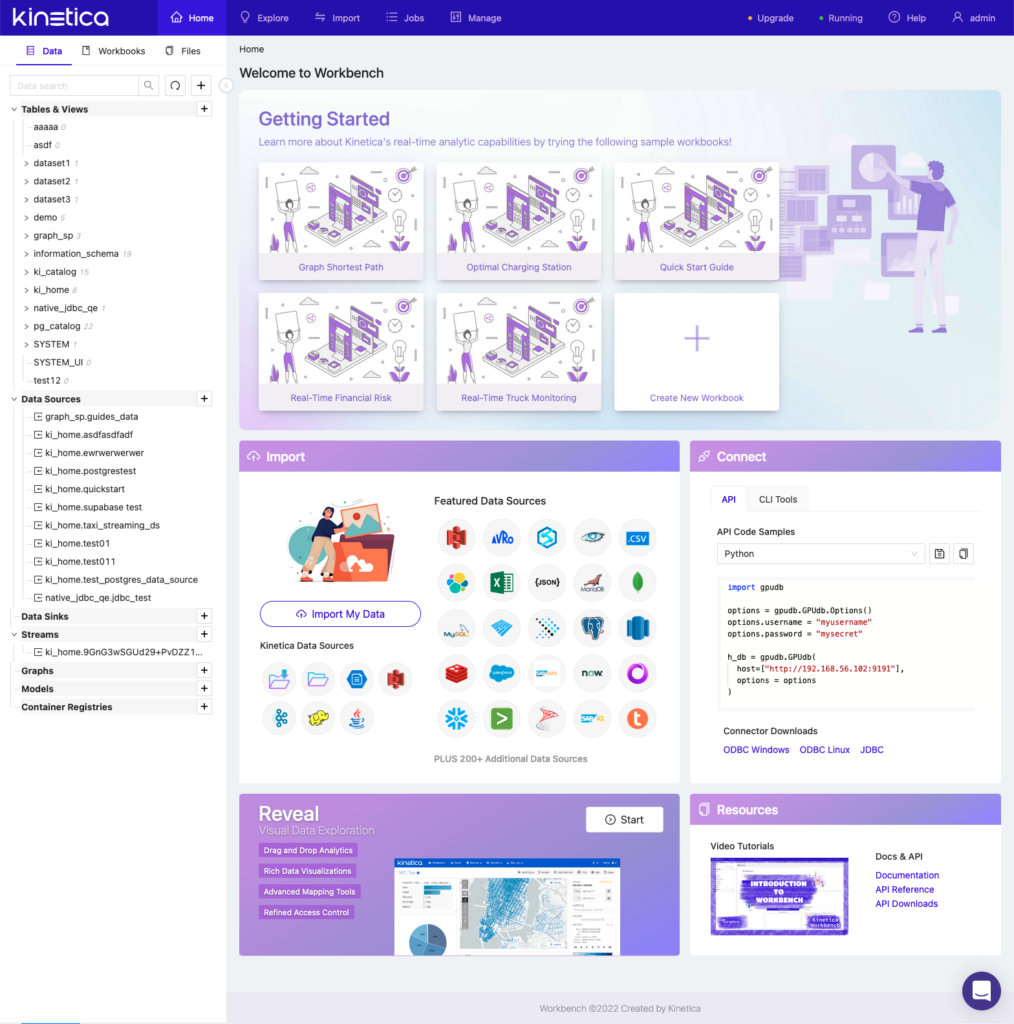
Using the interface
Kinetica’s workbench also comes with a point and click interface for connecting to native and JDBC data sources. This is an easy code free way to create a data source and start loading data from it into Kinetica.
Try it Yourself
The following repo contains a workbook that you can load into Kinetica to try this out on your own. You can run Kinetica in the cloud for free.
Resources
You can find more information about loading data into Kinetica from our documentation website.
Contact us
We’re a global team, and you can reach us on Slack with your questions and we will get back to you immediately.


