Where Matters: The Significance of Location in Vehicle Telemetry Data Analysis

The proliferation of sensors in automobiles has ushered in a new era of data-rich vehicles, offering immense benefits in terms of analyzing this wealth of information and creating data-driven products and features. Modern connected vehicles are equipped with a multitude of sensors, including those for engine performance, safety, navigation, and connectivity. These sensors continuously generate a vast array of data, encompassing everything from speed and fuel consumption to environmental conditions and driver behavior. This data, when harnessed effectively, enables automakers and tech companies to develop innovative products and features that enhance safety, convenience, and overall driving experience. By analyzing this data, insights can be gleaned about vehicle performance, predictive maintenance, energy efficiency, and even real-time traffic conditions, leading to the development of intelligent features like adaptive cruise control, predictive maintenance alerts, and advanced driver-assistance systems (ADAS). Moreover, the potential extends beyond the vehicle itself, as this data can be leveraged to create new services, such as usage-based insurance, fleet management solutions, and smart city initiatives that rely on […]
True Ad-Hoc Analytics: Breaking Free from the Canned Query Constraint

Many database vendors often boast about their support for ad-hoc querying and analytics, but in practice, true ad-hoc capability remains elusive. While the term “ad-hoc” implies the ability to generate novel, unanticipated questions on the fly, the reality is that most databases require that data requirements be well-defined in advance. These requirements are then used to engineer the data for performance in addressing these known questions. Data engineering, in this context, takes on various forms such as denormalization, indexing, partitioning, pre-joining, summarizing, and more. Put another way, data engineering exists to overcome the performance limitations of traditional databases. These techniques are employed to make data retrieval and analysis more efficient for anticipated queries. However, this approach falls short of the genuine ad-hoc flexibility that many users desire. Over time, users of data have adapted to a model where their expectations have been managed to follow a somewhat linear process. This process typically involves documenting their data requirements, which are then prioritized among numerous other demands. Users may have […]
Ask Anything of Your Data
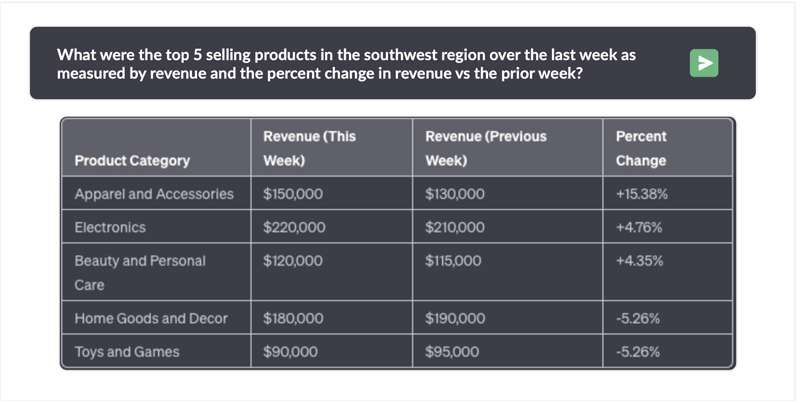
The desire to query enterprise data using natural language has been a long-standing aspiration. Type a question, get an answer from your own data. Numerous vendors have pledged this functionality, only to disappoint in terms of performance, accuracy, and smooth integration with current systems. Over-hyped solutions turned out to be painfully slow, causing frustration among users who expected conversational interactions with their data. To overcome performance issues, many vendors demo questions known in advance, which is antithetical to the free form agility enabled by generative ai. Accuracy issues have been just as vexing, with wild SQL hallucinations producing bizarre results or syntax errors leading to answers that are completely incorrect. Enterprises and government agencies are explicitly banning the use of public LLMs like OpenAI that expose their data. And when it comes to integration, cumbersome processes introduce significant complexity and security risks. Kinetica has achieved a remarkable feat by fine-tuning a native Large Language Model (LLM) to be fully aware of Kinetica’s syntax and the conventional industry Data […]
NVIDIA GPUs: Not Just for Model Training Anymore

In the rapidly evolving landscape of data analytics and artificial intelligence, one technology has emerged as a game-changer: Graphics Processing Units (GPUs). Traditionally known in the data science community for their role in accelerating AI model training, GPUs have expanded their reach beyond the confines of deep learning algorithms. The result? A transformation in the world of data analytics, enabling a diverse range of analytic workloads that extend far beyond AI model training. The Rise of GPUs in AI GPUs, originally designed for rendering images and graphics in video games, found a new purpose when AI researchers realized their parallel processing capabilities could be harnessed for training complex neural networks. This marked the dawn of the AI revolution, as GPUs sped up training times from weeks to mere hours, making it feasible to train large-scale models on massive datasets. Deep learning and generative AI, both subsets of AI, rapidly became synonymous with GPU utilization due to the technology’s ability to handle the intensive matrix calculations involved in neural […]
Kinetica’s Contribution to Environmental Sustainability: Pioneering Energy Efficiency in the Data Center and in the Field

In an era marked by growing concerns about environmental sustainability, companies across industries are seeking innovative ways to reduce their carbon footprint and contribute positively to the environment. Kinetica stands out as a trailblazer in this pursuit, particularly in the realm of compute efficiency and energy optimization. Let’s delve into how Kinetica is making substantial strides in the “E” (environmental) part of ESG (Environmental, Social, and Governance) through its unique approaches. Compute Efficiency Through Vectorization One of the primary ways Kinetica addresses environmental concerns is through its groundbreaking approach to compute efficiency. Traditional computing methodologies often require a vast number of processors to handle complex data analytics tasks, resulting in significant energy consumption and heat generation. Kinetica’s revolutionary vectorization technology, however, is turning this paradigm on its head. Kinetica was designed from the ground up to leverage parallel compute capabilities of NVIDIA GPUs and modern ‘vectorized’ CPUs. Vectorization is a computing technique that processes multiple data elements simultaneously, enhancing performance by exploiting parallelism within modern processors. This approach […]
GPU Accelerated Analytics – A Comparison of Databricks and Kinetica

GPUs have continued to rise in interest for organizations due to their unparalleled parallel processing power. Leveraging GPUs in an enterprise analytics initiative allows these organizations to gain a competitive advantage by processing complex data faster and extracting valuable insights against a larger corpus of data that can result in break-through insights. Both Databricks and Kinetica are platforms that leverage NVIDIA GPU (Graphics Processing Unit) capabilities for advanced analytics and processing of large datasets. However, their specific approaches and focus areas differ with respect to leveraging the GPU. Primary Purpose: Databricks is primarily known for its unified analytics platform that integrates Apache Spark for big data processing and machine learning tasks. While Databricks does support a plug-in for GPU-accelerated processing for certain machine and deep learning workloads, its design center is focused on CPU based data engineering and data science on large-scale data processing tasks. Databricks supports SQL through Spark SQL, and has streaming capabilities, but neither of which is optimized for the GPU. Typically, the GPU use […]
Dealing with Extreme Cardinality Joins

High cardinality data can be more difficult to efficiently analyze because many unique elements increase the computational cost for analysis, and make it more challenging to identify useful insights from the data. Cardinality refers to the number of unique elements in a set. For instance, low cardinality data sets include the names of a few countries, or data on the weather where there are only a few distinct values (such as sunny, cloudy, rainy, etc.), or data on the ages of a group of people where there are only a few distinct age groups. Historically, an example of high cardinality data might be a social security number or a driver’s license number where the number of unique identifiers number in the hundreds of millions. Today, the prevalence of digital devices and the internet has made it possible for people and machines to generate vast amounts of high cardinality data through their online activities that result in unique combinations of device IDs, timestamps, and geo-coding. This has resulted in […]
Do you need a streaming database?

Streaming databases are close cousins to time-series databases (think TimescaleDB) or log databases (think Splunk). All are designed to track a series of events and enable queries that can search and produce statistical profiles of blocks of time in near real-time. Streaming databases can ingest data streams and enable querying of the data across larger windows and with greater context compared to analyzing streams of data in motion, all within a compressed latency profile. How are Streaming Databases different than Conventional Analytic Databases like Snowflake, Redshift, BigQuery, and Oracle? Conventional analytic databases are batch oriented, meaning the loading of data occurs periodically in defined windows. Many conventional databases support frequent loading periods, known as micro-batch. This is in contrast to streaming databases that are always receiving new data as it is generated with no queuing prior to load. Further, conventional analytic databases lock the tables that are being loaded. When the tables are locked during the load process, they remain available to query by the end user […]
What to look for in a database for spatio-temporal analysis?

As sensor data, log data and streaming data continues to grow, we are seeing a significant increase in demand for tools that can do spatial and time-series analytics. The cost of sensors and devices capable of broadcasting their longitude and latitude as they move through time and space is falling rapidly with commensurate proliferation. By 2025, projections suggest 40% of all connected IoT devices will be capable of sharing their location, up from 10% in 2020. Spatial thinking is helping innovators optimize existing operations and drive long promised digital transformations in smart cities, connected cars, transparent supply chains, proximity marketing, new energy management techniques, and more. But traditional analytic databases are not well-suited to dealing with spatial and time-series data, which can be complex and difficult to analyze. As a result, there is rising interest in new types of analytic databases that are specifically designed to handle this type of data. Such systems need advanced algorithms and specialized data structures to efficiently store and analyze spatial and time-series […]
The Internet of Things in Motion (IoTiM)

Sensors have evolved from taking readings over time to taking readings over space and time. Understanding this trend and the resulting impacts are essential for innovators seeking to create value in the next wave of IoT products and services. From Transactions to Interactions to Observations The earliest form of data used for analytics described transactions. Examples of transactions include when an order is placed, inventory is replenished, or revenue is collected. The era of big data emerged when organizations began to harness interactions data. Interactions make a record of decisions made by humans. Examples of interactions include liking something on social media, watching a show through a streaming service, browsing the web, or playing a video game. What drives data volume growth today is proliferation of devices that capture observations. Curt Monash defines it as data that is more about observing humans and machines than recording the choices of humans. For example, sensors are able to monitor our pulse, the flow of traffic at an intersection, drone traffic […]