How to deploy natural language to SQL on your own data – in just one hour with Kinetica SQL-GPT

You’ve seen how Kinetica enables generative AI to create working SQL queries from natural-language questions, using data set up for the demonstration by Kinetica engineers. What about your data? How can you make Kinetica respond to real SQL queries about data that belongs to you, that you work with today, using conversational, natural-language questions, right now? You’re about to see how Kinetica SQL-GPT enables you to have a conversation with your own data. Not ours, but yours. With the built-in SQL-GPT demos, the data is already imported, and the contexts that help make that data more associative with natural language, already entered. When your goal is to make your own data as responsive as the data in our SQL-GPT demos, there are steps you need to take first. This page shows you how to do the following: STEP 1: Import your Data into Kinetica Kinetica recognizes data files stored in the following formats: delimited text files (CSV, TSV), Apache Parquet, shapefiles, JSON, and GeoJSON [Details]. For Kinetica to […]
The mission to make data conversational

I think one of the most important challenges for organizations today is to use the data they already have more effectively, in order to better understand their current situation, risks, and opportunities. Modern organizations accumulate vast amounts of data, but they often fail to take full advantage of it because they struggle finding the right skilled resources to analyze it that would unlock critical insights. Kinetica provides a single platform that can perform complex and fast analysis on large amounts of data with a wide variety of analysis tools. This, I believe, makes Kinetica well-positioned for data analytics. However, many analysis tools are only available to users who possess the requisite programming skills. Among these, SQL is one of the most powerful and yet it can be a bottleneck for executives and analysts who find themselves relying on their technical teams to write the queries and process the reports. Given these challenges Nima Neghaban and I saw an opportunity for AI models to generate SQL based on natural […]
Getting answers from your data now: Natural language-to-SQL

Generative AI has raised people’s expectations about how soon they can get answers to the novel questions they pose. What amazes them first is how fast GenAI responds to them. When people see this, they wonder why they can’t have a similar experience when asking questions about their enterprise data. They don’t want to have to document their requirements, and then fight for resources to eventually be prioritized, only to find themselves waiting for their database teams to engineer the environment to answer yesterday’s questions. They want to ask questions and get answers. Ad hoc answers Most databases aren’t good at answering questions to questions that no one anticipated beforehand. Take a look at the traditional methods folks have used for decades, for optimizing database processes and accelerating performance, which includes indexing, denormalization, pre-aggregation, materialized views, partitioning, summarizing. All of this is about overcoming performance limitations of traditional analytic databases. Pre-engineering data is essentially trading performance for agility. Whenever you pre-engineer data to improve performance for the queries […]
Ask Anything of Your Data
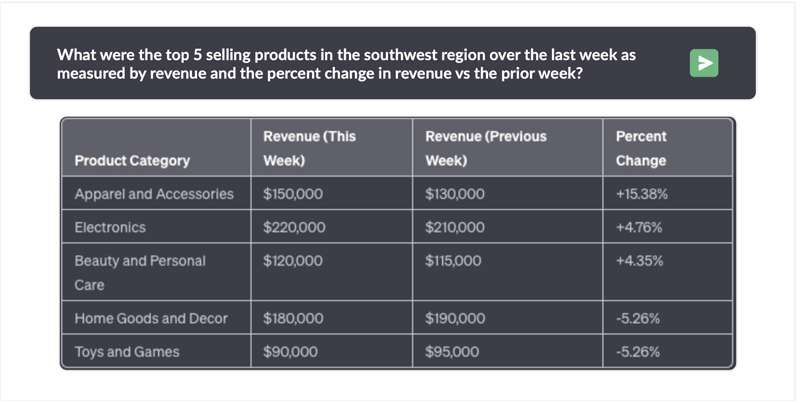
The desire to query enterprise data using natural language has been a long-standing aspiration. Type a question, get an answer from your own data. Numerous vendors have pledged this functionality, only to disappoint in terms of performance, accuracy, and smooth integration with current systems. Over-hyped solutions turned out to be painfully slow, causing frustration among users who expected conversational interactions with their data. To overcome performance issues, many vendors demo questions known in advance, which is antithetical to the free form agility enabled by generative ai. Accuracy issues have been just as vexing, with wild SQL hallucinations producing bizarre results or syntax errors leading to answers that are completely incorrect. Enterprises and government agencies are explicitly banning the use of public LLMs like OpenAI that expose their data. And when it comes to integration, cumbersome processes introduce significant complexity and security risks. Kinetica has achieved a remarkable feat by fine-tuning a native Large Language Model (LLM) to be fully aware of Kinetica’s syntax and the conventional industry Data […]


