When machine learning models fall victim to anomalies, real-time up to date data, accelerated model training, and an agile deployment process become critical in the response effort.
Introduction
Even the most slick, well designed forecasting models can fall victim to anomalies like the COVID-19 pandemic. Think back to shortages in toilet paper and face masks. When crisis hits, human behavior changes and markets quickly shift. In order to respond effectively, organizations need the ability to leverage data in real time. Traditionally, demand can be modeled using a variety of techniques:

- ARIMA (Auto-Regressive Integrated Moving Average) great for forecasting over short periods of time using auto-correlations in time series data
- SARIMA (Seasonal Auto-Regressive Integrated Moving Average) an extension of the ARIMA model that takes seasonality into account
- Regression (Linear Regression, Random Forest, Neural Networks) Statistical methods for predicting future values based on historical trends

Each technique has situational advantages. Whether its a hurricane impacting utility consumption, forest fires or earthquakes disrupting supply chains, or in this case, a pandemic creating new needs in our hospital systems, one thing is very clear – organizations need better agility to adapt quickly and develop data driven solutions in response to crisis. In this example, I am going to train a Recurrent Neural Network on the GPU to predict the number of ventilators needed in response to COVID-19.

Recurrent Neural Network (RNN)
Recurrent Neural Nets are great for time series data. They maintain a step-by-step summary of what they have seen over a specified window in order to predict future demand in the series. Typically as data volumes increase and complexity is added, training time can be a big draw back when trying to develop deep learning models. In the case of a crisis, or anomaly, the time it takes to get one of these models from inception to production has proved challenging across industries. To accelerate this process, I can use Kinetica’s Active Analytics Workbench to develop my RNN using pre-configured notebooks with automatically managed GPU resources. Libraries like TensorFlow 2.0 are great in this case because the built in Long Short Term Memory Networks (LSTM) and Gated Recurrent Unit (GRU) layers have been updated to leverage CuDNN kernels by default when a GPU is available. https://www.tensorflow.org/guide/keras/rnn.

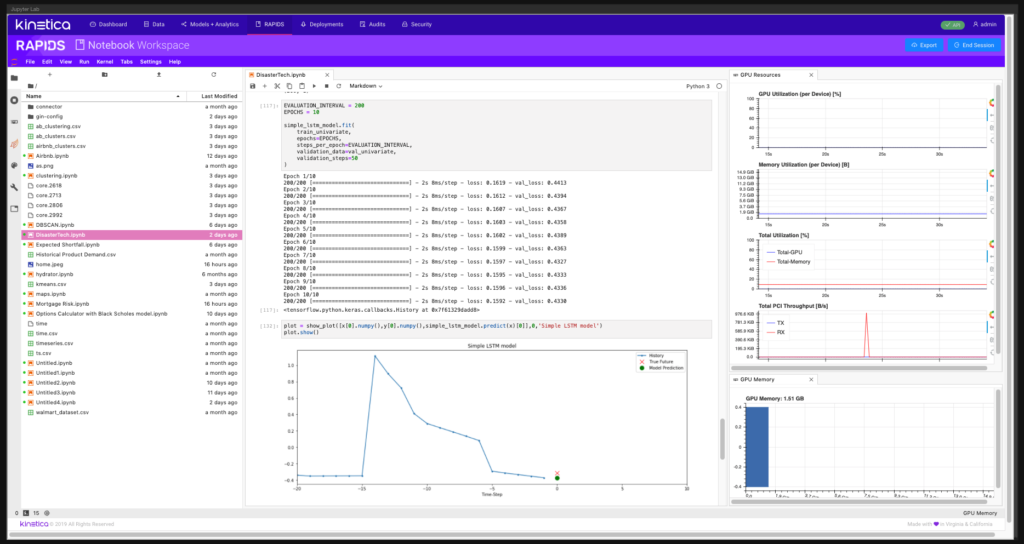
Kinetica native Jupyter environment with pre-configured libraries and automated GPU orchestration

Data Ingestion
In order to develop this model quickly in response to a crisis, I need to be able to quickly pull the latest, up-to-date data. For this, I can leverage a highly distributed database like Kinetica, where I can use connectors for Spark, Kafka, NiFi etc. to achieve real time ingest, perform large, multi-head batch ingest, or even quick drag and drop functionality for CSVs. Once the data is sitting in a table inside Kinetica I can then hydrate a dataframe directly. https://www.kinetica.com/docs/connectors/index.html

Fast Track To Production
After my model has been tuned and trained, the deployment process is very straight forward. Under the hood Kinetica’s Active Analytics Workbench uses Docker and Kubernetes for model deployment and orchestration. Once the model has been containerized and published to Docker, the user can pull that container and launch it on Kubernetes with a few clicks. I first pick my compute target whether that be CPU or GPU. For example, if I was using a simple linear regression model with scikit-learn or an ARIMA model, I can deploy that on CPU. In this case, I am using a GPU capable RNN so I can simply point and click to switch to GPU for my compute. Next I can take advantage of Kinetica’s out of the box replication option to achieve higher distribution and maximize performance. If my machine has 4 available GPUs for example, I can replicate this deployment 1 – 4x. Last I select the type of deployment I want to launch. In On-Demand mode I can hit my deployment from an endpoint and get quick what if scenarios by passing a JSON payload. For Batch and Continuous mode, I can select the table in Kinetica that I will be passing to my model to infer on, or point to a table that I am streaming data to. In a Continuous mode deployment, the model will act as a table monitor and fire off inferences as new data hits the table.

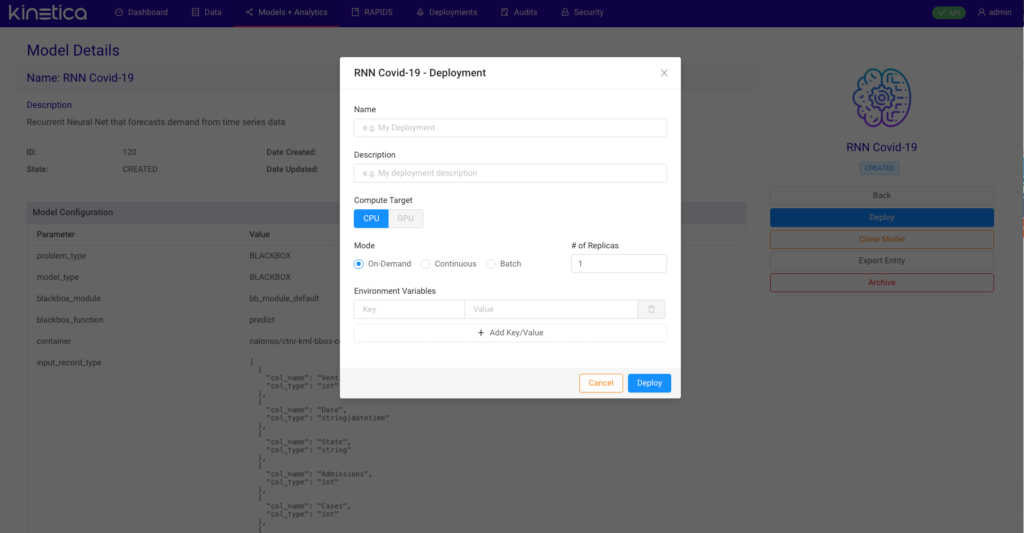
Kinetica’s Active Analytics Workbench deployment UI

This deployment process is incredibly useful in the case of a crisis. As data rapidly changes, models need to be quickly retrained. The ability to co-locate your data and models on a highly distributed database creates a fluid repeatable process. The ability to quickly spin these models up and down, retrain, deploy and evaluate the results side by side accelerates traditional time to insight. We can also take it a step further by using Kinetica’s geospatial and location intelligence functionality. It is easier to break down analysis at the country, state and county level to uncover information that can geospatially enrich existing machine learning models. One company that is excelling at this is Disaster Technologies. Watch below to see how Disaster Technologies uses Kinetica to provide users a centralized platform for access to critical data and analysis in the case of a an unforeseen event with global impact.

Disaster Tech COVID-19 Platform: Predict Hospital Admissions & Plan Responsive Supply Distribution
Big shout out to our director of Emerging Analytics, Nohyun Myung, for a killer demo and presentation

If you want to try some time series forecasting for yourself using Kinetica, download a free trial here: https://www.kinetica.com/trial/

Join us for a Tech Talk on June 17: Enabling Data Powered Emergency Response, A Smart Application Example With Kinetica to see a detailed breakdown of the technical aspects of the Disaster Tech demo http://go.kinetica.com/enabling-data-driven-emergency-response
Nick Alonso is a solutions engineer on the Emerging Analytics team at Kinetica.


