We exist in a world where data is being generated at an exponential rate. Many of these datasets contain time and location information that provide context to the data. Location is the glue that enables us to see new patterns from growing collections of information. Most notably, location-aware datasets also allow us to discover patterns that become visible when combined with other fragmented pieces of location-based data.
One of the most pervasive datasets we can leverage as a common baseline in the big data community is social media. Fortunately for us, nearly every piece of social media data generated today contains locational context.
As an example, we’ll explore a sample historic dataset of Twitter events that is approximately 4Bn unique records. Leveraging Kinetica GPU-accelerated database, we can both ingest and subsequently analyze and interact with large-scale datasets that are location aware with unprecedented performance.
The screen capture below illustrates a heat map visualization of those 4Bn Tweets, mostly concentrated in North America, which was rendered on-the-fly and in less than 500ms. Nothing was cached or rendered ahead of time.

Data exploration can be via NLP text searches, SQL-92 compliant queries, and most importantly for this blog post, advanced geospatial functions such as aggregations (AKA binning), distance calculations, nearest neighbor solves and much more through Kinetica’s APIs.
An important piece of information to note is that Kinetica treats geospatial data as primitives, which means support for both simple (points) and complex geometries (lines, polygons, tracks, geometry collections, etc.) But more importantly, the native geospatial functions have been built to execute in parallel across the GPU nodes to address the performance-at-scale issues that are prevalent in the industry. Let’s use an example…
The previous screen capture showed an on-the-fly rendering of the 4Bn Tweets in under half a second. Let’s do some data exploration by providing some text search criteria to filter our results.
Below is a capture of the map results that is updated once we apply an NLP text filter on the term “organic”. You can see a fairly dramatic change in the dataset, all of which happens in under 300ms. The number of results being displayed went from 4Bn+ to approximately 289,000.

Here’s one of many of the results in the Los Angeles area of our dataset, confirming through the attributes of the Tweet text that our NLP text search filtered our results correctly.

What we’ll do next is add a series of different text-based searches to my filter, so we can create a result-set that contains all of the Tweets with a reference or context towards organic foods. The purpose of this is to ultimately generate a map that illustrates where positive and negative sentiment social media events occur around my topic of choice, and try to find some correlation with additional data that we’ll explore later on.
For example, we’ll add a fuzzy search of “farm & table” ~3, which will search for Tweets where the words farm and table occur within 3 words of each other (basically we’re looking for “farm to table”).
Another quick validation of the Tweets confirm that our search is providing the results that we want.


We’ll do this with about a dozen total different text-search criteria, aggregating them all into a single resulting dataset (which ends up being trimmed down to ~6.5 million records from the 4+ billion we started with). The most critical part in all of this is that all of our slicing and mining on the 4+ billion records take anywhere from 50-350ms. We are processing queries against massive datasets that complete nearly as quickly as we can ask for the results.

Next, we might want to apply some spatial filtering to our result, narrow into a specific geography, region, or market area, and then do a deeper dive on the data. Being able to perform on-the-fly aggregations on massive datasets is critical in geospatial data analysis workflows, as you typically explore and test your analysis methods on smaller samples of data to validate your analysis for your entire dataset
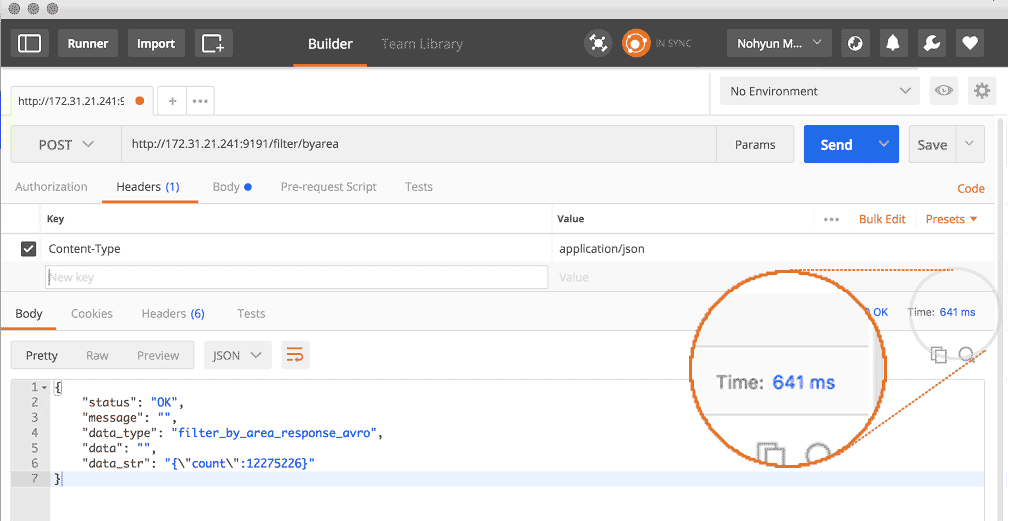
Here we can leverage our API calls (or even SQL supported Spatial Functions) to do your data wrangling and execute a spatial filter on-the-fly via filter/byarea. This particular API method allows me to pass in a geometry (e.g. the State of Oregon) and filter a table’s results (historic Twitter events) to the bounds of that geometry.
You’ll see from my Postman collection, that I was able to spatially query over 4 Billion records within a relatively complex geometry (the State boundary of Oregon) in well under one second. My result is a spatially filtered table with a little over 12 Million records.
At the beginning of this blog post, we mentioned how the importance of location-awareness is magnified once we want to analyze multiple data sets that are seemingly unrelated. Here’s where things get interesting.
Kinetica exposes its capabilities, such as map rendering, query capabilities, and geospatial functions, through our RESTful API flavors (pick your favorite from Java, Python, C++, JavaScript, NodeJS, etc.). This means that users and organizations that have already invested in traditional enterprise platforms can easily integrate Kinetica’s capabilities to those existing systems, applications and services.
For example, say you’re a savvy GIS user and you have existing apps or services that are based one of the more traditional systems (Esri, MapBox, or a traditional Open Source option such as GeoServer). Kinetica maps support the open standards by way of OGC compliant services which means that integrating Kinetica map visualizations on millions/billions/trillions of spatial features in real-time within your GIS ecosystem is nothing more than a single URL string via our APIs.
Need proof? Let’s use Esri ArcGIS Online, and simply add our Kinetica OGC-compliant map service with a single URL request that hits our Kinetica REST API.

We end up with our 4+ billion record Twitter dataset, but in this case we’re rendering the raw features by default. So you’re seeing every single Tweet displayed on the map, as opposed to the previous captures which showed a heat-map style concentration of the Tweet events.

Again, the most impressive part of this is that we’re able to dynamically visualize all of these records in sub-second timeframes!
(Amusing side-note for the GIS folks: the pre-cached tiles of the basemap that took hours, if not days, to generate took longer to render/return than the Kinetica map 🙂 )
We’ll change the map that gets displayed to the aggregate Tweet events that contained context around organic foods and was confined to the state of Oregon.

You’ll also notice that we changed the rendering style of the map to be a class-break renderer. What this illustrates is positive sentiment-value Tweets with regard to our topic will show up as green, and negative sentiment-value Tweets will show up as purple.
Why is this important? The OGC-compliant web map services allow us to not only alter the style of map that we want displayed (e.g., a heatmap, raw features, class-break rendering, etc.) but we can specifically define the classification and rendering details in the map request. This results in users being able to customize how they want their data to display to support their analysis.
As a final step, we want to take a completely disparate dataset and see what sort of quick-glance assertions we can make about the data as it relates to the social media events.
We’re overlaying a dataset that shows the location of USDA authorized organic food producers in the Portland area to the map. Why are we doing this? We simply want to understand if there’s any sort of obvious geographic correlation to make between where positive and/or negative sentiment social media events occur in relation to where these organic food producers might be located.

The fusing of these different datasets, that really have no relation to one another other than their location, tells us that there’s a stronger correlation in areas where there are clear gaps or a lack of organic food producers.
Of course this is in no way any deeply vetted analysis or validated insight. But these sorts of clues can begin to lead us to ask more questions or add additional fragments of information or intelligence.
What if we overlaid the location of grocers or shops that primarily sold organic products? What if we tied in demographic data about spending habits or household income of the people that lived in these areas of interest? You could go on and on with adding additional context and data-rich information that is location-aware to further confirm or deny your analysis.
In the following examples, you’ll see that we spatially joined our Twitter results to a collection of block group boundaries. We then use use a class-break renderer to show the aggregated results of our data to those block groups. This is useful because it can certainly be difficult when dealing with millions of point events to understand patterns and extract valuable insights as there is simply too much content on the map.
Below we are showing the average sentiment value, normalized by the number of Tweets at the block group level. The darker areas illustrate higher sentiment to Tweet volume ratios.
So what does this tell me? My gut reaction when I looked at all of the tweets by sentiment may actually have been a little premature. It’s our natural instinct to see large clusters/concentrations of those events and make an assumption about what that means in our minds. Here if you look at the downtown area of Portland, based on our normalized aggregation, it has a lower sentiment-to-volume ratio, whereas the western area of the city has much higher sentiment-to-volume ratio (albeit a much lower volume).


The ability to use location as the glue that binds these datasets together has always been available and important. Where we are today is in the midst of a paradigm shift, and with Kinetica you can leverage location-aware information with the ever-increasing datasets and perform spatial analysis on them at the speeds to support next-generation Location-Based Analytics.
See more examples and learn more about what you can do with large geospatial datasets at the upcoming NVIDIA/Kinetica webinar, Advanced Analytics and Machine Learning with Geospatial Data: A World of Possibilities, on October 5, 2017, 10am PT. Register here.


