When you’ve got a large amount of files, like images, in a folder on your cluster where Kinetica’s running, you might want to access that data through the Kinetica database. With the Kinetica File System (KiFS) there’s no need for ingest! You can mount that directory to Kinetica and the files will automatically be mirrored in a Kinetica table, utilizing KiFS. In this blog, I’ll walk through the details on how to do this. Alternately, you can also watch this 7 minute video:
Configuration & Setup
In gpudb.conf you need to tell Kinetica that you want to use the KiFS and what the directory you want to mount is:
enable_kifs = true
kifs_mount_point = /opt/gpudb/kifs
After a restart of Kinetica:
/opt/gpudb/core/bin/gpudb restart all
you can then copy your files into that mounted directory, unless you mounted a folder that already contains your data. For more details around KiFS configuration have a look at the documentation: https://www.kinetica.com/docs/tools/kifs.html
Browsing the Mounted Table
All folders under your mount point will show up under the ‘filesystem’ collection when you browse your tables in GAdmin:
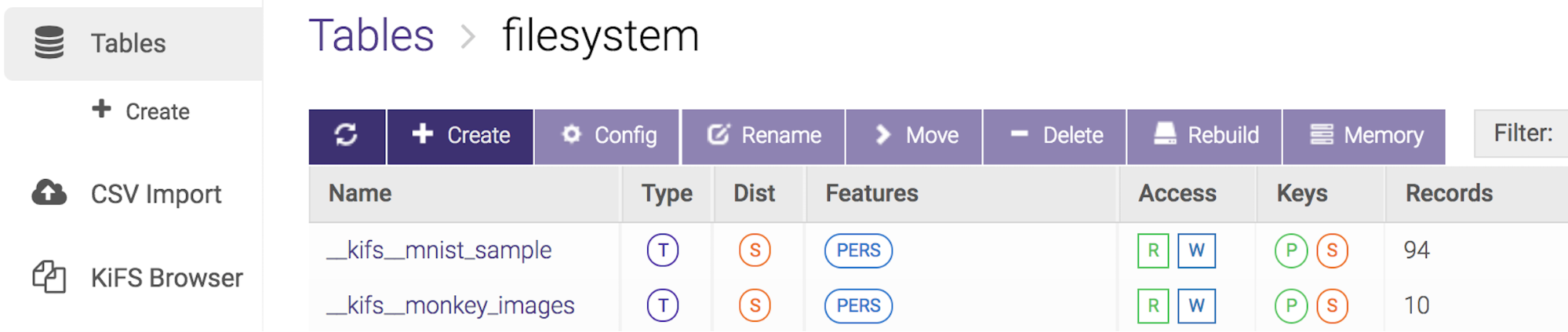
However, the recommended way to browse the data in KiFS is to use the ‘KiFS Browser’ which allows you to look into the mounted folders and also to upload/download files:
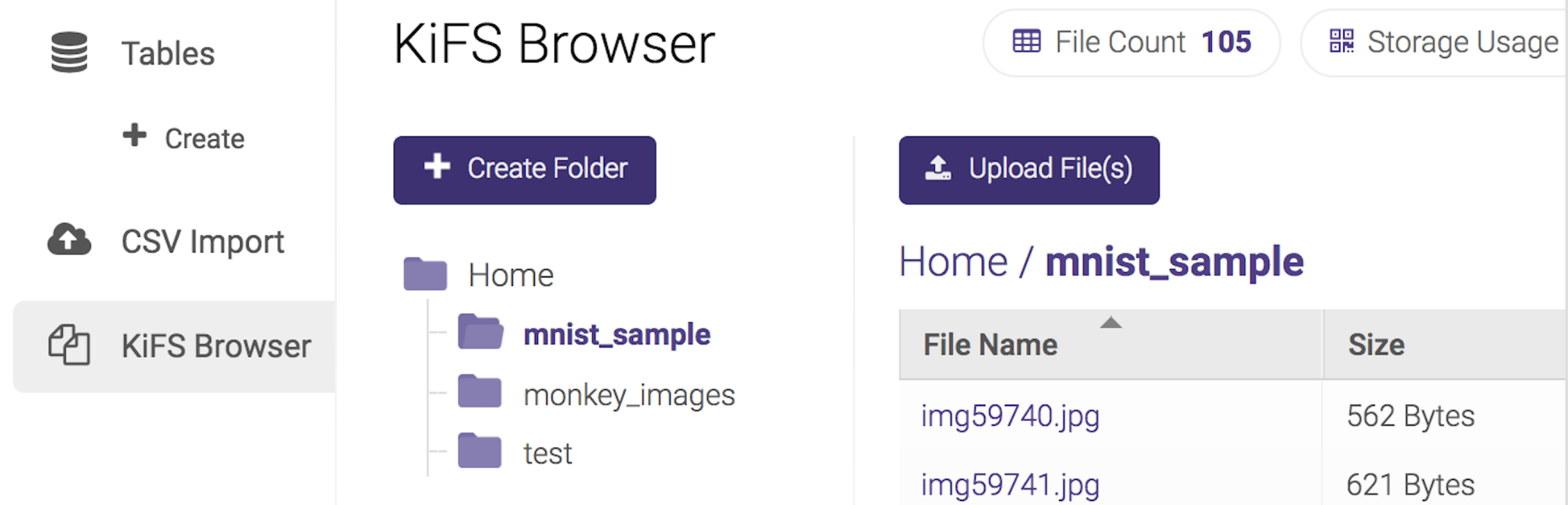
Accessing the Data via API
User-Defined Function (UDF) API – Python
The Kinetica UDF API allows you to implement a distributed UDF, which means multiple instances of that UDF may run across your cluster. In this situation you need to keep in mind:
- Each UDF locally accesses a fraction of the data – that of their respective TOM.
- Data is accessed direct and fast from the table, through the proc_data handle.
- Data arrives as byte objects which requires a manual conversion to images.
The code snippet below illustrates how you read image data from KiFS that’s mirrored in a table.

In this example ‘__kifs__mnist’ is the table name and ‘file’ is the column name that holds the image byte data.
KiFS Direct Access
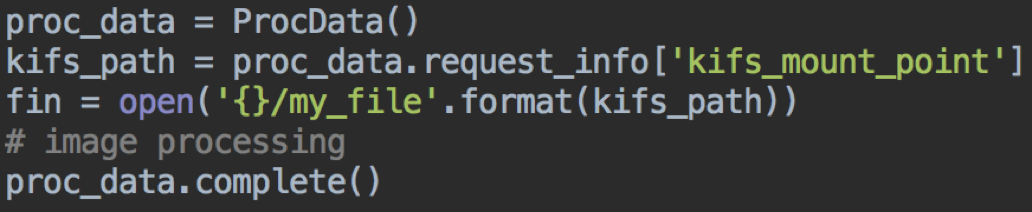
You also have the option to directly read the data from the file system. This could be done both, via a distributed or a non-distributed UDF. It’s important to understand in that case:
- Each UDF instance (in the distributed case) accesses all data. That means you would have to manually take care of the ‘division of labor’.
- Reading the data directly from the file system is the fastest way of access.
As the below code snippet shows, you’d still use the proc_data handle. Just not for data access, but to retrieve the information of where the actual mount point is. Reading the data can then be done through the standard (Python) file system API:
GPUDB API – Python
In a non-distributed UDF you could also use the Kinetica (Python) GPUDB API which allows you to query the data with SQL-like logic. It’s actually not recommended to access data from KiFS when maximum performance is required because the data is not accessed in parallel at a per rank level, but in serial in a single process. This is how you’d read the images using that API:

In this screenshot the value for ‘options’ is empty but you could put in a where condition there (filter), for example saying you only want to read images below a specific file size.
Image Classification Use Case
A situation where it could be useful to use KiFS to work with large amounts of image data is for image classification. To learn more, check out my recent blog post on the mechanics of Kinetica with TensorFlow integration.


