There is a new buzzword going around in the analytics space coined the data “lakehouse.” Databricks, who recently just secured a $1 Billion Series G round of funding at a $28 Billion valuation, is bringing this idea to market in an effort to simplify the traditional 3-tiered architecture strategy that is prevalent in fortune 500 enterprises today. Below we will outline the benefits of accelerating your data lake investment with a streaming data warehouse, delivering on average 10x faster performance than Spark on 1/10th of the underlying infrastructure1.
Common Challenges with Traditional Tiered Architecture
Enterprise organizations commonly design their analytics stack with a traditional 3-tiered approach. The first layer acts as a data lake, where all data is stored as a source of record. Data is then typically ingested using ETL techniques into an analytics layer, consisting of a spider web of data warehouses, databases, and advanced analytical frameworks designed to derive insights from that data. Once those analytics take place the results are pushed out to a services layer where a combination of microservices, visualization tools, and custom applications consume these insights. Several key challenges teams face when using legacy technologies include:
- Huge total cost of ownership incurred at scale
- Data accessibility, data duplication, and data becoming stale
- Ingest and analysis with heavy latency and slow performance at scale
With the continued emergence of IoT applications, exploding data volumes, and a shift from passive to predictive analytics, organizations are rethinking their architecture strategy across every industry.
Kinetica: The Streaming Data Warehouse
Kinetica is a streaming data warehouse, purpose built for complex advanced analytics. This is a developer’s paradise. With out of the box connectors, APIs and native language bindings, Kinetica is designed to integrate with tools and technologies that are already in-house — delivering the fastest, most comprehensive set of analytics capabilities in the industry.

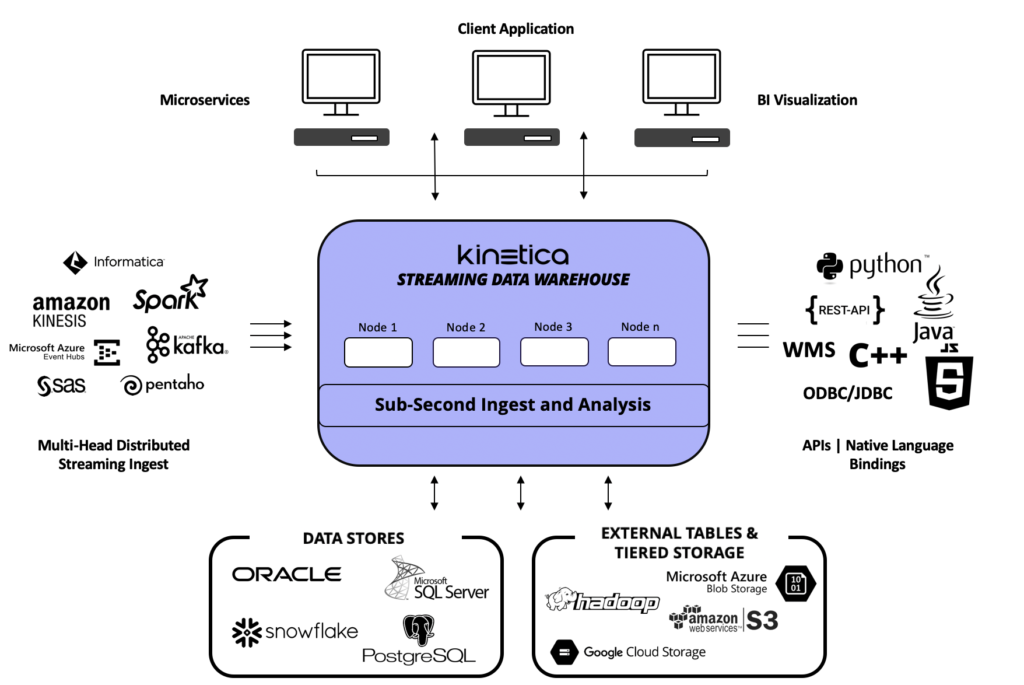
Kinetica has been purpose-built from the ground up for over a decade with custom, vectorized kernels that consistently outperform Spark on less underlying infrastructure. Customers have seen 1 hour workloads that require 700+ nodes of Spark execute in seconds on 16 nodes of Kinetica. Partners have optimized their analytics architecture by consolidating 100 nodes of Cassandra and Spark into 8 Kinetica nodes and still experience better performance — and all of this performance comes with native advanced analytical tools that can be applied to high-velocity streaming data.
Acceleration Layer on your Data Lake
With data volumes exploding at an exponential rate, data accessibility has become a major challenge for data analysts, scientists, and engineers alike. Kinetica offers industry leading connectors to quickly ingest data from enterprise organization’s data lakes. With multi-head distributed ingest, users can quickly load billions of records into their Kinetica cluster in parallel. Even on a single node, Kinetica can ingest millions of records per second. Kinetica also provides performant and cost effective analytics for organizations with petabytes of data sitting in their data lake using Kinetica’s tiered storage.
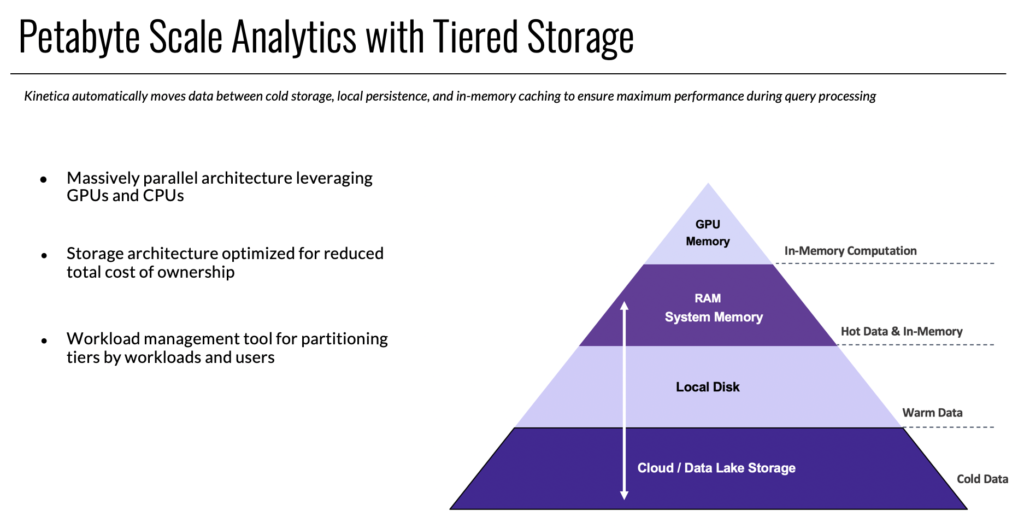
Kinetica can still be used in a single data model approach and is capable of referencing and creating tables from externally managed sources like HDFS, S3, Blob storage etc. but with tiered storage, administrators have the ultimate flexibility and control to manage their workloads across their resources. Kinetica optimally moves data between cold storage, local persistence, and in-memory caching to ensure maximum performance during query processing. For example: tables that are only accessed every 6 months do not need to be living in memory. That would be incredibly expensive and would consume capacity from other workloads that may need vectorized computational performance. Users can define a tiering strategy to their data and Kinetica will automatically facilitate the data movement between tiers. Tiered storage can also be used as a resource management tool where users can define how much of each tier individual workloads and even users can access.
Accessing Data From External Data Lakes
For teams who want to minimized data duplication and would rather leave their data where it sits, Kinetica can reference external tables for fast read operations and analysis. See the example below to quickly create and reference an external table sitting in Amazon S3 on Kinetica.
CREATE DATA SOURCE kin_ds
LOCATION = 'S3://'
USER = 'USER KEY'
PASSWORD = 'ACCESS KEY'
WITH OPTIONS
(
BUCKET NAME = 'kinstart',
REGION = 'us-east-1'
);
show data source kin_ds;
CREATE or REPLACE MATERIALIZED EXTERNAL TABLE demo.taxi_data
(
"pickup_datetime" TIMESTAMP,
"dropoff_datetime" TIMESTAMP,
"pickup_longitude" REAL,
"pickup_latitude" REAL,
"dropoff_longitude" REAL,
"dropoff_latitude" REAL
)
FILE PATHS 'taxi_data.parquet'
FORMAT PARQUET
WITH OPTIONS
(
DATA SOURCE = 'kin_ds',
REFRESH ON START = false
)
All of your Analytics in One Place
With the rapid emergence of IoT applications and a fundamental shift in how enterprises are using data, legacy systems are choking in an effort to keep pace. Data warehouses that boast real-time analytics capabilities are typically referring to 15–60+ seconds of latency. There are two key reasons for this type of slow performance. First, most of these technologies require that you stream your data to a data lake, acting as a staging area, before you can trigger an ingest. From this staging area, you can then load your data into a table. The second underlying issue attributing heavy latency is that most data warehouses lack native advanced analytical tools. For any type of geospatial analysis, graph theory, machine learning or time-series workloads, users need to migrate data to and from additional partner frameworks requiring their own licensing, compute and storage. This creates both higher latency and higher total cost of ownership. Kinetica offers over 100+ highly performant geospatial operators, patented graph solvers, an entirely in-house push-button AI/ML deployment framework, and a dominantly performant, ANSI 92 SQL compliant interface with robust function support.
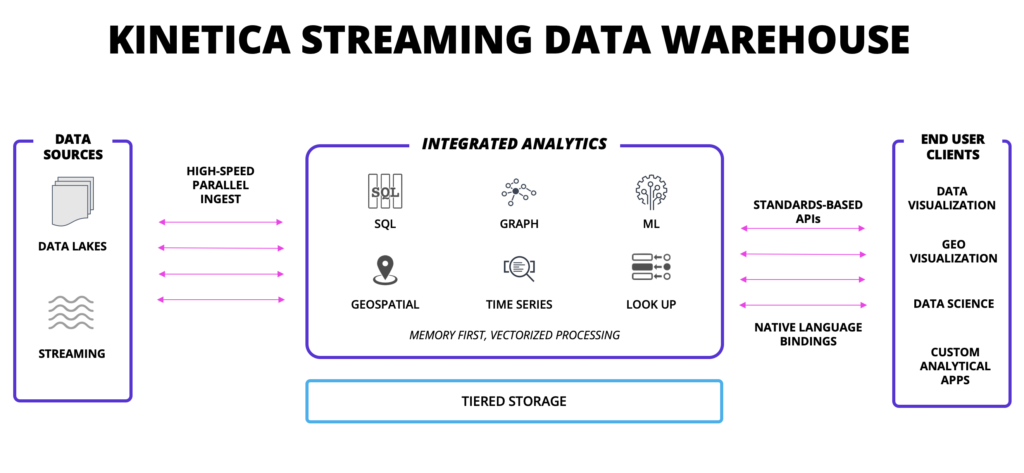
Simultaneously Ingest and Analyze
Kinetica provides users the ability to subscribe directly to multiple real-time sources. There is no staging area required. With lockless architecture, Kinetica can simultaneously ingest and analyze data as fast as you can throw it, with a suite of native tools to tackle a variety of analytics. Whether it be geospatial analysis and visualization, graph theory, machine learning, time-series, or even complex OLAP, Kinetica provides the tools and horsepower that deliver real-time insights. Rather than streaming data to your data lake, out to your analytics tools then back to your data lake, experience the speed of ingesting data directly into Kinetica, analyzing that data, and then egressing those results to both the downstream applications and to your data lake. Cutting out that extra ingest step and return loop will not only reduce latency but will also greatly reduce total cost of ownership.
Let Us Prove it!
If you are interested in learning how Kinetica is on average 10x faster than Spark on 1/10th the infrastructure feel free to reach out. Grab your data, pick your workload, and stand the two technologies up against each other to see the difference.
Kinetica Trial: https://www.kinetica.com/try/
- These figures are based on internal TPC-DS benchmarks conducted in October 2020.


